TheDeveloperBlog.com
C-Sharp | Java | Python | Swift | GO | WPF | Ruby | Scala | F# | JavaScript | SQL | PHP | Angular | HTML
DBMS Cluster File Organization
DBMS Cluster File Organization with DBMS Overview, DBMS vs Files System, DBMS Architecture, Three schema Architecture, DBMS Language, DBMS Keys, DBMS Generalization, DBMS Specialization, Relational Model concept, SQL Introduction, Advantage of SQL, DBMS Normalization, Functional Dependency, DBMS Schedule, Concurrency Control etc.
Cluster file organization

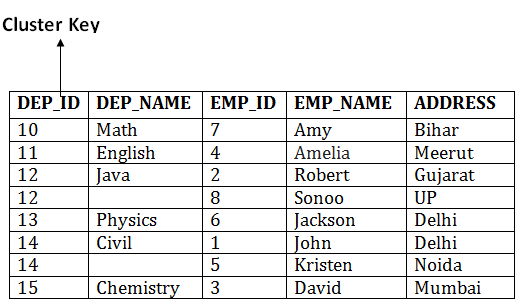
In this method, we can directly insert, update or delete any record. Data is sorted based on the key with which searching is done. Cluster key is a type of key with which joining of the table is performed. Types of Cluster file organization:
Cluster file organization is of two types: 1. Indexed Clusters:In indexed cluster, records are grouped based on the cluster key and stored together. The above EMPLOYEE and DEPARTMENT relationship is an example of an indexed cluster. Here, all the records are grouped based on the cluster key- DEP_ID and all the records are grouped. 2. Hash Clusters:
It is similar to the indexed cluster. In hash cluster, instead of storing the records based on the cluster key, we generate the value of the hash key for the cluster key and store the records with the same hash key value. Pros of Cluster file organization
Cons of Cluster file organization
Next TopicIndexing in DBMS
|



Related Links:
- DBMS Multivalued Dependency
- DBMS Inclusion Dependence
- DBMS SQL Set Operation
- Top 52 DBMS Interview Questions (2021)
- DBMS Transaction Processing Concept
- DBMS States of Transaction
- DBMS Schedule
- DBMS Conflict Serializable Schedule
- DBMS View Serializability
- DBMS Recoverability of Schedule
- DBMS Tutorial | Database Management System
- DBMS Failure Classification
- DBMS Concurrency Control
- DBMS Lock based Protocol
- DBMS Log-Based Recovery
- DBMS Checkpoint
- DBMS Timestamp Ordering Protocol
- DBMS Validation based Protocol
- DBMS Thomas Write Rule
- DBMS Multiple Granularity
- DBMS Sequential File Organization
- DBMS Recovery Concurrent Transaction
- DBMS Characteristics of SQL
- DBMS File organization
- DBMS Heap File Organization
- DBMS Hash File Organization
- DBMS B+ Tree
- DBMS RAID
- DBMS B+ File Organization
- DBMS Indexed Sequential Access Method
- DBMS Cluster File Organization
- DBMS Hashing
- DBMS Static Hashing
- DBMS Dynamic Hashing
- DBMS SQL Introduction
- DBMS Advantage of SQL
- SQL Commands: DDL, DML, DCL, TCL, DQL
- DBMS SQL Operator
- DBMS SQL Insert
- DBMS SQL Update
- DBMS SQl Datatype
- DBMS SQL Table
- DBMS SQL Select
- DBMS SQL Index
- DBMS SQL Sub Queries
- DBMS SQL Clauses
- DBMS Generalization
- DBMS Specialization
- DBMS vs Files System
- DBMS Architecture
- DBMS SQL Delete
- DBMS SQL View
- DBMS Three schema Architecture
- DBMS Data model schema and Instance
- DBMS Join Operation
- DBMS Notation for ER diagram
- DBMS Relational Calculus
- DBMS Data Independence
- DBMS Language
- DBMS ER model concept
- DBMS Mapping constraints
- DBMS Keys: Primary, Foreign, Candidate and Super Key
- DBMS Aggregation
- DBMS Join Dependency
- DBMS Convert ER into table
- DBMS Relationship of Higher Degree
- DBMS Relational Model concept
- DBMS Relational Algebra
- DBMS Integrity Constraints
- DBMS Functional Dependency
- DBMS Inference Rule
- DBMS Normalization: 1NF, 2NF, 3NF and BCNF with Examples
- DBMS Transaction Property
- DBMS Testing of Serializability
- DBMS 1NF
- DBMS 2NF
- DBMS SQL Aggregate function
- DBMS SQL Joins
- DBMS 3NF
- DBMS BCNF
- DBMS 4NF
- DBMS 5NF
- DBMS Relational Decomposition